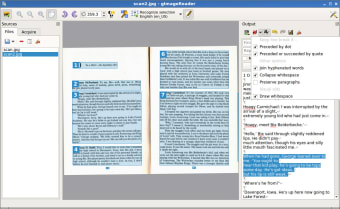
ファイルを簡単に開いて抽出する
gImageReaderはビジネスと生産性Manisandroまたは正式にはSandroManiとして知られているソフトウェアによって開発されました。この便利なデスクトップユーティリティを使用すると、画像を開くとPDFファイルを簡単に開くことができます。これにより、テキストを抽出する任意の領域を選択することもできます。
提供されるシンプルなフロントエンドにより、完全な状態にすることができます。業界で最も強力なOCRアプリケーションの1つに直感的にアクセスできます。これは、高価な無料の代替手段です。 > Adobe AcrobatDCのようなオフィススイート。 p>
gImageReaderをどのように使用しますか?
このオープンソースプロジェクトは、最高の機能セットを提供しながら、ユーザーエクスペリエンスを合理化することです。 gImageReaderの使用は2つの方法で開始でき、どちらも1分程度で数ステップで簡単に実行できます。 ページ全体のテキストを抽出する場合は、テキストの抜粋を取得するPDFまたは画像を選択するだけです。 p>
その後、[すべて認識]をクリックする必要があります。ボタン。一方、ドキュメントの一部のみを抽出 strong>する場合は、マウスを使用して選択範囲を描画し、[認識]をクリックする必要があります。選択ボタン。また、 TesseractOCR言語がインストールされている場合、gImageReaderにはその言語を自動的に検出する機能があります。
さらに、いくつかの操作をサポートしますソースドキュメント。たとえば、90度の回転、ズームインまたはズームアウト strong>を実行でき、画像をカスタマイズするための基本的なコントロールへのアクセスを提供します。さらに、調整 strong> 明るさを調整できます。一部のファイルの視認性を向上させるために、コントラストとドキュメントの解像度の変更を行います。
テキストを抽出するためのより合理化されたプロセス
gImageReaderは、システムに追加するのに便利なコンピュータプログラムになるはずです。提供されるシンプルなフロントエンドGUIを使用すると、PDFファイルまたは画像ファイルからテキストをより簡単かつ直感的な方法で認識して抽出できます。これは、有料オフィススイートの優れた代替手段 strong>になります。  p>